

SCIENCE CHINA 2020 的文章,出自黄老师组的 zhangzheng 和 高信~
结合该论文梳理目前任务型对话系统的最新进展和挑战。
依旧给我的知乎打个广告,传送门~https://zhuanlan.zhihu.com/p/120657306
嘻嘻,某公众号也转载了该篇,sih觉得还是看原文理解更深一点~
背景
本文总结了目前任务型对话系统最新的进展和挑战,讨论了三个相关的关键问题:
- 如何提高数据使用效率,在资源不足的情况下对任务型对话系统进行建模;
(2)如何为多轮对话的对话策略进行建模,使其在任务完成上表现的更好;
(3)如何将领域的本体知识集成到pipeline模型和端到端模型中。
同时回顾了当前对话评估的方法和目前广泛使用的语料库的最新进展。
一些介绍
- 任务型对话系统的目标:
旨在帮助用户完成特定领域中的某些任务,例如餐厅预订,天气查询和航班预订,使其对现实世界中的业务有价值。
- 任务型对话系统与开放域对话系统相比的区别:
开放域对话系统的主要目的是最大化用户的参与度,而任务型对话系统更针对于完成一个或多个域中的某些特定任务。 通常,面向任务的对话系统以结构化的本体集合为基础,这些结构化的本体集合定义了该任务的领域知识。
- 任务型对话系统的一般结构:
任务型对话系统从体系结构分类大致可分为两类: pipeline 和 end-to-end
- 在pipeline的方法中,模型通常由几个组件组成:
自然语言理解(NLU)、对话框状态跟踪(DST)、对话框策略(Dialog Policy)和自然语言生成(NLG)。它们以流水线的方式组合在一起,如图所示。NLU、DST和NLG模块通常在组合之前单独进行训练,而dialog policy则在组合系统中进行培训。
2. 在 end-to-end的方法中,对话系统以端到端方式进行训练,而不指定每个单独的组件。通常端到端方法的训练过程被表述为:在给定对话上下文和后端知识库的情况下生成的系统应答。
Main Challenges
归结上述的分析,总结起来就是任务型对话系统中的三个关键问题:
- Data Efficiency: 但是在面向任务的对话系统中,特定于域的数据通常很难收集并且注释起来很昂贵。 因此如何解决数据源匮乏we,提高数据使用效率是主要的挑战之一。
- Multi-turn Dynamics:与开放域对话相比,面向任务的对话的核心特征是它在多轮策略中强调goal-driven。 在每个轮次,系统动作都应与对话历史保持一致,并应引导后续对话获得更大的任务奖励。但是基于RL的方法,构建训练环境开销较大以及当前奖励的定义也不够完善。此前的研究提出了许多解决方案,以解决多轮交互式训练中的这些问题来学习更好的策略,包括基于模型的 planning,连续的奖励估计和端到端的策略学习。
- Knowledge Integration:任务型对话系统必须查询知识库(KB)以检索一些实体以生成响应。 在pipeline方法中,KB查询主要是根据DST的结果构造的。 那么与pipeline模型相比,端到端方法没有了模块化的组件,因此需要细粒度的注释和领域专业知识。 由于没有构造查询的显式状态表示形式,因此这种查询过程存在很多问题。
研究现状
Data efficiency
与开放域对话系统的研究不同,面向任务的对话系统是数据驱动方法,通常需要细粒度的注释来学习特定域中的对话模型,所以我们需要对话行为(dialog act)和状态标签(state labels), 但是通常很难在特定域中获得大规模的带注释的语料库,另外细粒度的标注也需要大量的人力资源。因此目前针对该挑战提出的一些方法: Dialog Transfer Learning, Unsupervised Methods, User Simulation。
对于低资源问题:
在面向任务的对话系统中一般应用转移学习,通过将知识从源任务转移到目标任务来解决低资源问题。 例如,当旅馆域中的数据有限时,如何将餐馆预订系统改为旅馆预订。在这种情况下,这两个域的本体相似,共享许多对话动作和槽位。 在这种情况下,迁移学习可以大大减少这种适应所需的目标数据量。除域级别的迁移外,知识还可以在许多其他维度上进行迁移,包括个性化和跨语言迁移。 主要应用的算法:多任务学习,参数共享,模型共享,元学习。
- Multi-domain dialog state tracking using recurrent neural networks.提出通过在多个域的数据集上进行多任务学习来学习DST模型,跨域传递知识,从而提高所有任务的性能。
- Goal-oriented chatbot dialog management bootstrapping with transfer learning. 提出直接从源域模型共享参数来初始化目标模型。
- Cross-domain dialogue policy transfer via simultaneousspeech-act and slot alignment. 提出对于没有共享slot的领域间,建立状态转移方程和映射函数。
个性化迁移:
- Personalizing a dialogue system with transfer reinforcement learning(ACL2018).所有的用户都有一个通用的Q函数,每个特定的用户都有一个个性化的Q函数。当转移到一个新的用户,只需要少量的数据获得个性化的Q-function。
- Fine grained knowledge transfer for personalized task-oriented dialogue systems.
- Personalizing dialogue agents via meta-learning.
此外基于元学习的方法在解决低资源的问题上也有所应用,
- Meta-learning for low-resource natural language generation in task-oriented dialogue systems. 通过在NLG上应用MAML算法,使得模型可以在低资源环境下获得较好的结果。
2. Unsupervised Methods
对于缺少细粒度标注的问题:
- 生成对抗网络(GAN): 对话策略学习中的一个关键问题是设定奖励进行监督,在实际应用中就需要建立能够提供奖励信号的奖励估计模型。 此处无监督方法的应用在于,将对话策略视为生成器,并将奖励函数视为判别器,可以采用生成对抗网络(GAN)以无监督的方式学习奖励函数。
Adversarial learning of task-oriented neural dialog model.
Unsupervised dialogue spectrum generation for log dialogue ranking.
- 变分自动编码器(VAE): 在大多数研究中,对话系统的本体集是由专家构建的。目前的最新的研究进展是从未标记的语料库中自动学习对话结构来协助人类专家进行此过程。
Unsupervised dialog structure learning. 提出通过变分自动编码器(VAE)的方法来学习对话过程的有限状态机。 使用未经中间注释的原始对话语料库预先训练了基于VAE的对话模型,然后根据潜在变量可以发现几个对话状态。
- 基于预训练的方法: 在预训练方法中使用无监督的预训练任务,例如 mask language modeling (MLM) 和 next sentence prediction (NSP),从大规模的未标记语料库提取广泛的语言特征,再应用到对话任务中。
A transfer learning approach for neural network based conversational agents.
Towards the use of pretrained language models for task-oriented dialogue systems.
3. User Simulation
用监督的方法构建用户模拟器,提供基于RL的对话策略模型不限次数的用于训练交互的环境,缓解data-hungry 的问题。
- Sequence to sequence modeling for user simulation in dialog system.
- Neural user simulation for corpus-based policy optimisation of spoken dialogue system.
- Deep dyna-q: Integrating planning for task-completion dialogue policy learning.
Multi-turn Dynamics
在开放域对话系统中,研究更多地集中在生成合理,一致且语义丰富的响应上,以最大程度地提高用户参与度。 面向任务的对话系统,则重点放在完成特定任务上这个对话过程可以表述为⻢尔可夫决策过程(MDP):在每个时间步长,通过采取某些对话动作,系统从当前状态过渡到了新的下一状态。因此,强化学习通常用于解决对话系统中的MDP问题。 最新研究主要集中在以下主题上:(1) 规划对话策略学习以提高样本效率;(2)奖励稀疏性问题;(3)端到端系统的对话策略学习。
在应用RL的训练过程中,使用用户模拟器并不能完全模拟真实的对话行为,因此存在的偏差也会影响训练效果。目前研究的解决方法是在RL训练阶段,学习实际用户行为的同时,使用环境模型进行规划来交替训练对话策略。 在Deep Dyna-Q(DDQ)模型中有一个基于真实用户训练的world model捕捉环境动态, planing则是指对话策略则是通过直接RL(实际用户)和模拟RL(world model)交替来进行训练的。
基于planning的另一种方法是决策时间的规划,仅展望未来几个有限的步骤,并将这些步骤作为策略模型的附加函数来做出决策,而不是等所有对话结束再获得明确的奖励。 Towards end-to-end learning for efficient dialogue agent by modeling looking-ahead ability.
Hierarchical text generation and planning for strategic dialogue.
2. Reward Estimation
在基于RL的对话模型中,奖励对于策略学习至关重要。 定义奖励函数的一种典型方法是在对话成功时分配较大的正向奖励,并在每轮次中分配较小的负奖励,以鼓励对话轮次尽可能短。但是实际应用中,有时无法有效地估算奖励,或者规则的奖励信号与真实用户主观给出的奖励信号有时不一致。为了解决上述问题,目前的研究中尝试的方法有:
一种方法是使用带注释的数据进行离线学习:
Predicting user satisfaction in spoken dialog system evaluation with collaborative filtering.
通过将对话句子和中间注释作为输入特征,将奖励学习表述为有监督的回归或分类任务。 可以从人工标注获得带注释的奖励。 但是由于输入特征空间很复杂,需要手动注释,开销较大。
还有另一项工作是使用在线学习进行奖励估算:
Reward estimation for multi-domain task-oriented dialog. EMNLP2019
主要思想将预测的状态动作与实际做比较,提供不确定性的度量来作为奖励信号。此外还有采用对抗学习来进行对话奖励的估算。
3. End-to-end Dialog Policy Learning
端到端的对话训练方法则不再拆分为各个模块,而是对整个系统进行建模。 与开放域对话建模类似,以单词级别作为输入,将策略学习和回复生成结合在一起作为解码器。但是与开放域对话相比,任务型对话的策略学习对完成任务更重要,将两个操作结合在一起会相互影响性能。 因为对于特定的训练示例,损失可能来自策略学习的error或回复语言生成的error之一,但参数的反向传播会影响两者。因此一些工作尝试用潜在变量模型,从端到端框架中分离策略和语言的学习:
Hierarchical text generation and planning for strategic dialogue.提出用潜在变量模型将对话表达的语义从其语言实现中分离出来。
此外端到端系统学习另一个存在的问题是很难进行显式的知识库查询,比较熟悉的端到端对话系统模型 Sequicity: Simplifying task-oriented dialogue systems with single sequence-to-sequence .它的解决办法提出了一种两阶段的CopyNet,在解码之前产生一个明确的状态表示, 具体是首先对用户的输入生成belief span表示当前对话状态,然后通过belief span来查询知识库,再生成系统响应。 一些研究还提出了一种复合状态表示形式,用于软KB查询:
Sequence-to-sequence learning for task-oriented dialogue with dialogue state representation
Knowledge Integration
任务型对话系统的另一个主要问题是如何将领域知识集成到对话模型中,如图所示。
在pipeline框架中,是通过根据DST的结果从知识库中查询知识,然后在NLG过程中,将查询到的实体集成到自然语言响应中,因此DST的效果影响了KB的抽取。传统的神经方法将DST定义为分类任务,但只能处理本体中的slot值,很难解决OOV问题,并且很难扩展到新域。 最近的研究尝试用端到端的对话系统解决该问题,但也存在诸多挑战,因为与pipeline方法不同,没有显式的对话状态表示形式来生成显式的知识库查询。 以下介绍的最新的进展包括:(1)DST的生成方法(2)端到端系统中的知识集成。
CopyNet和 Pointer network
DST跟踪每一个对话轮次中结构化的对话状态表示,目前的研究也是直接将自然语言作为DST输入而不使用NLU, 避免了NLU模块的累积误差。早期的方法通常采用分类方法解决DST问题:
Neural belief tracker:Data-driven dialogue state tracking. 通过⻔控机制对系统request和inform信息进行了显式建模。 但是这些方法只能处理该领域本体词汇表中预定义的slot值。
上面提到的Sequicity模型使用带有两阶段CopyNet的seq2seq模型,同时生成belief span和回复响应,应用复制网络解决OOV的问题。 另外还有研究提出,使用指针网络来提取之前未定义的slot值:
An end-to-end approach for handling unknown slot values in dialogue state tracking.
2. End-to-end Knowledge Integration
由于端到端方法中没有显式的结构化对话状态表示。 因此,目前的研究希望通过使用模型的中间潜在表示来和进行知识库交互,端到端的进行训练。主要应用 CopyNet和端到端memory networks,通过结合注意力机制将知识集成到对话系统中。
A copy-augmented sequence-to-sequence architecture gives good performance on task-oriented dialogue.
Mem2seq: Effectively incorporating knowledge bases into end-to-end task-oriented dialog systems.
Entity-consistent end-to-end task-oriented dialogue system with kb retriever.
Sequence-to-sequence learning for task-oriented dialogue with dialogue state representation.
一些最新的对话数据集比较
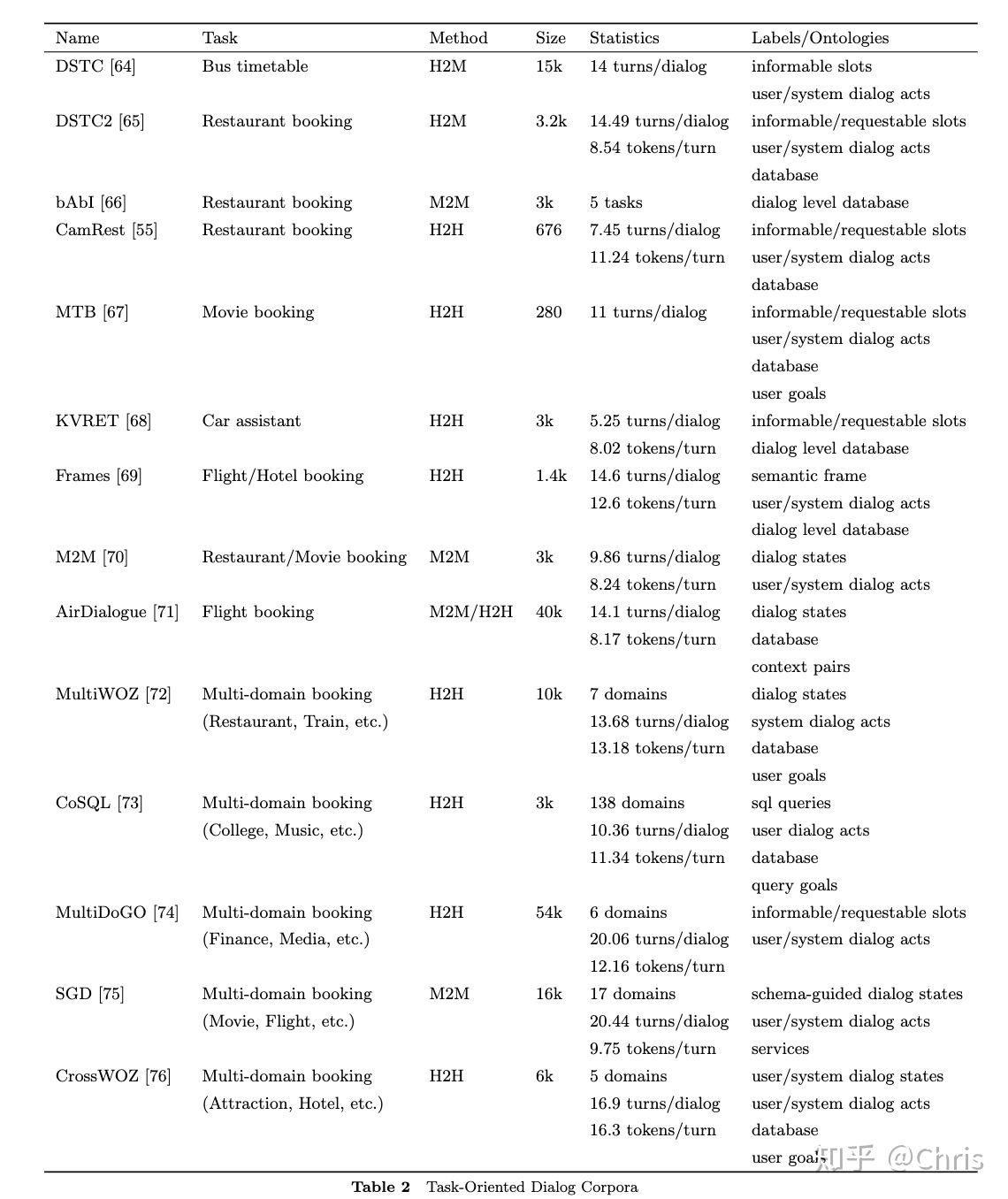 未来关注点:
未来关注点:
- Pre-training Methods for Dialog Systems.
A transfer learning approach for neural network based conversational agents.
Hello, it’s gpt-2–how can i help you? towards the use of pretrained language models for task-oriented dialogue systems. ACL2019
- Domain Adaptation
Zero-Shot Dialog Generation with Cross-Domain Latent Actions
- End-to-end Modeling
Sequicity: Simplifying task-oriented dialogue systems with single sequence-to-sequence .


